From Abstraction to Instantiation:
Learning Behavioral Representation for Vision-Language-Action Model
Abstract
Vision-Language-Action (VLA) models often suffer from performance degradation under distribution shifts, as they struggle to learn generalized behavior representations across varying environments. While existing approaches attempt to construct behavior representations through action-centric latent variables, they are often limited by short-horizon temporal fragmentation and static execution-alignment, leading to inconsistent behaviors in complex scenarios. To address these limitations, we propose BehaviorVLA, a framework that facilitates robust manipulation through the learning of a temporally coherent behavioral representations. Our approach features two symmetric components: (1) the Visuomotor Behavior Encoder (VBE), which utilizes a causal Mamba-based architecture to aggregate long-horizon trajectory information into a unified behavior representation; and (2) the Phase-conditioned Behavior Decoder (PBD), which decodes this representation into precise actions by dynamically aligning task-level priors with real-time execution progress. Experiments on RoboTwin 2.0, LIBERO, and CALVIN demonstrate state-of-the-art success rates of 58%, 98%, and 4.36 (Avg. Len), respectively. Notably, in real-world sim-to-real transfer, BehaviorVLA matches the performance of OpenVLA-OFT using only 50% of the demonstration data, showcasing its superior data efficiency and generalization.
Method
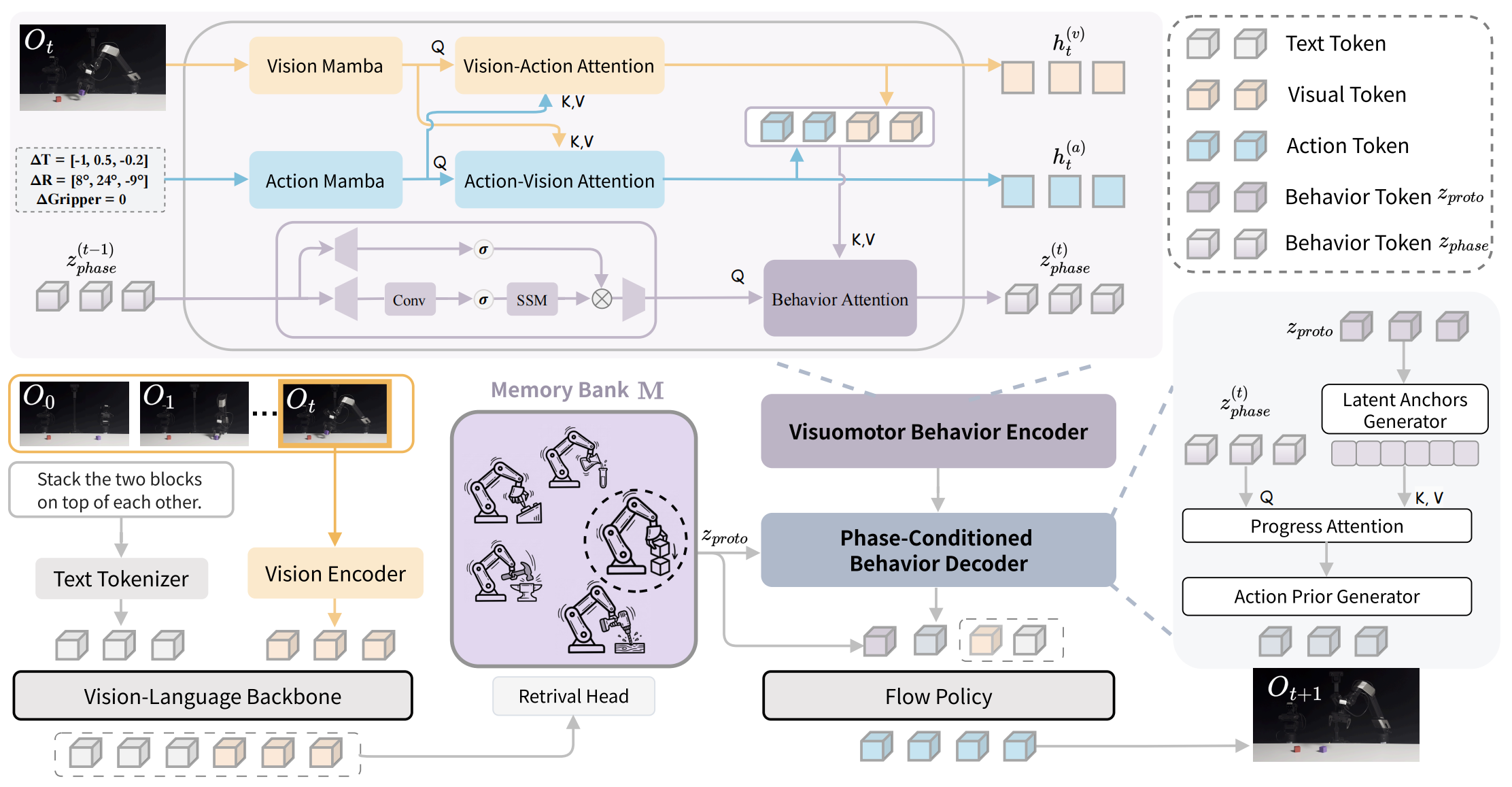
Experiments
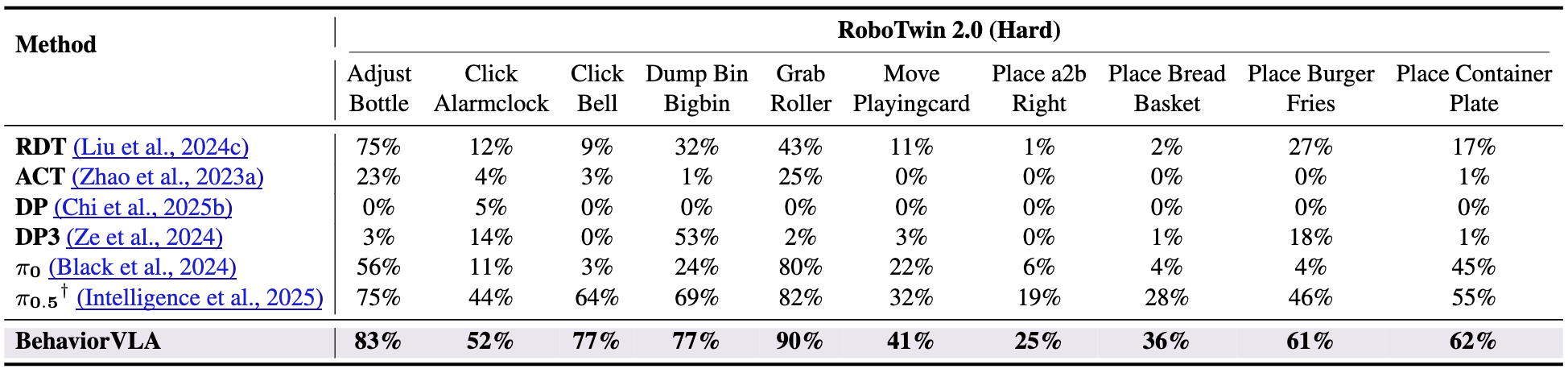
RoboTwin 2.0
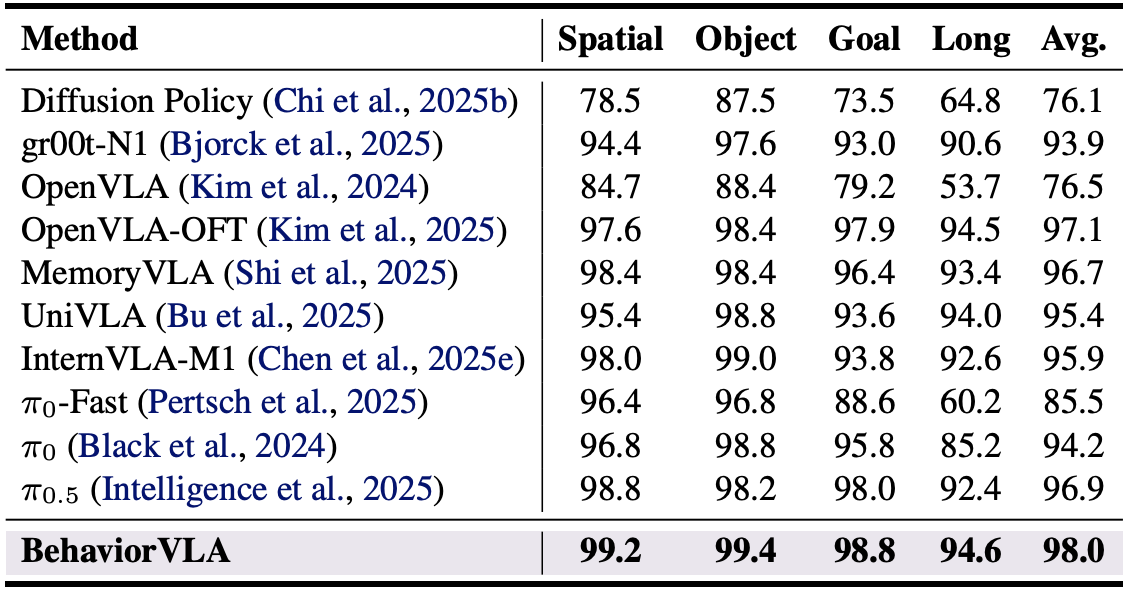
LIBERO
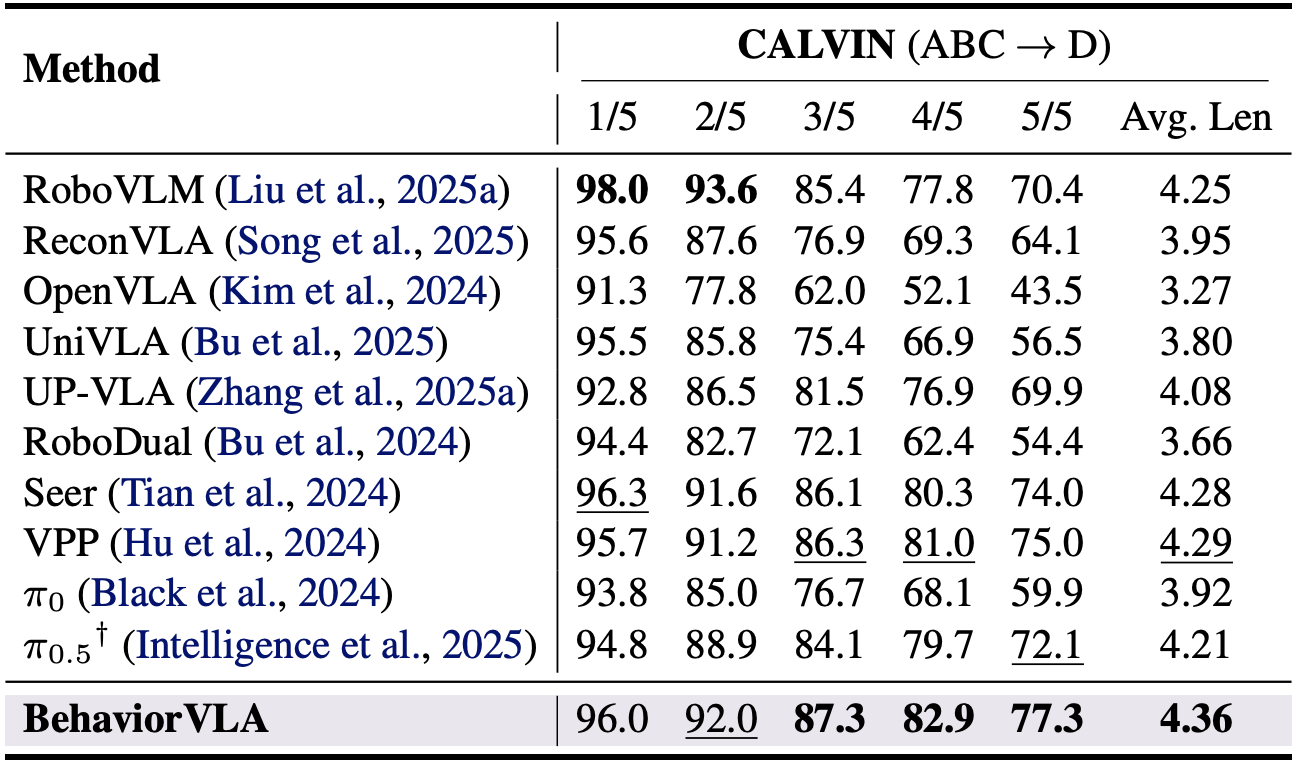
CALVIN
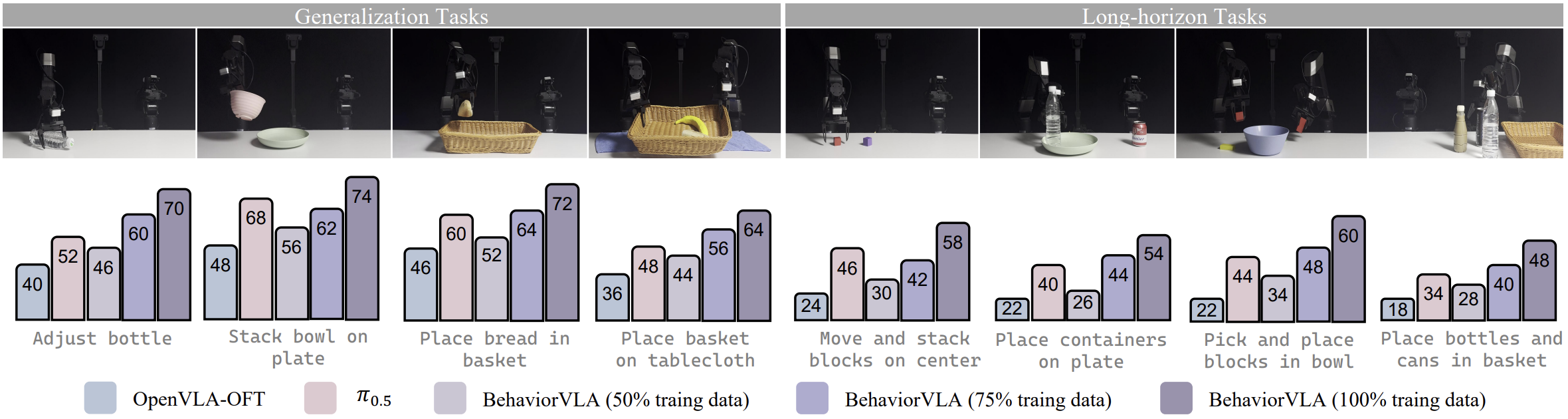
Real-World Evaluation
Conclusion
In this work, we introduce BehaviorVLA, a framework designed to enhance the robustness of VLA models by learning temporally coherent behavior representations. Through the synergistic design of the Visuomotor Behavior Encoder and Phase-conditioned Behavior Decoder, our approach effectively balances global behavior abstraction with precise, phase-aligned control. Extensive experiments demonstrate that BehaviorVLA achieves state-of-the-art performance across simulation benchmarks and significantly enhances sim-to-real transfer efficiency, matching leading baselines with only 50% of the fine-tuning data. These results suggest that explicitly modeling structured behavior representations is a scalable and data-efficient path toward robust robotic manipulation in Real-World.
Demo
Place bottles in basket
Stack bowl on plate